
시작하기에 앞서 오늘 공부할 개념들을 간단하게 소개하고 시작하도록 하겠습니다.
- 채널 : 코루틴 간에 데이터를 안전하게 보내고 받는 데 사용할 수 있는 파이프입니다.
- 액터: 채널과 코루틴을 사용하는 상태를 감싼 래퍼로 여러 스레드에서 상태를 안전하게 수정하는 매커니즘을 제공합니다.
- 뮤텍스 : 크리티컬 존(임계 영역)을 정의하여 힌 번에 하나의 스레드만 실행할 수 있도록 하는 동기화 매커니즘입니다. 크리티컬 존에 엑세스하려는 코루틴은 이전 코루틴이 크리티컬 존을 빠져나올 때까지 일시 정지됩니다.
1. 채널 Channel
동시성과 관련된 수많은 오류들은 서로 다른 스레드 간에 메모리를 공유할 때 발생합니다.
데드락, 레이스 컨티션(경쟁 상태), 원자성 위반은 공유 상태와 관련있습니다.
이들은 공유 상태가 유효하지 않기 때문에 발생하며, 상태가 읽관성을 잃어버리는 원인이 되기도 합니다.
이런 문제를 극복하기 위해 코틀린, 고와 같은 최신 프로그래밍 언어들은 채널을 제공합니다.
채널은 스레드가 서로 상태를 공유하는 대신 메시지를 주고받는 통신을 하도록 함으로써 동시성 코드를 작성하는 데 도움을 주는 도구입니다.
채널을 이해해보자
채널은 동시성 코드 간에 서로 안전한 통신을 할 수 있도록 해주는 도구라 하였습니다.
채널은 동시성 코드가 메시지를 보내 통신할 수 있도록 해줍니다.
채널은 실행 중인 스레드에 상관없이 서로 다른 코루틴 간에 메시지를 안전하게 보내고 받기 위한 파이프라인으로 생각할 수 있습니다.
채널이 어떻게 중요하고 현실적인 시나리오에서 사용될 수 있는지 예시를 통해 알아보겠습니다.
스트리밍 데이터 사례
특정 키워드에 대하여 10개의 콘텐츠 인덱서(content indexer)를 조회한 뒤 검색 결과를 (안드로이드 UI에) 보여주는 간단한 작업이 있습니다.
첫 번째 접근 방법은 각 콘텐츠 인덱서를 위한 코루틴을 시작해서 Deffered<List<ResultDto>>를 반환하고, 모든 코루틴이 완료되면 결과를 병합해서 UI에 보내는 것입니다.
각 인덱서가 응답을 반환하는 시간이 다르고, 일부는 상당히 오래 걸릴 수 있다는 문제점이 있습니다.
그렇기에 모든 코루틴이 완료될 때까지 기다려야 하는데, 결과 표시를 지연시켜서 사용자가 즉시 결과와 상호작용하는 것을 방해합니다.
더 좋은 해결책으로 다음과 같은 방법이 있습니다.
첫 번째는 검색 메서드의 반환값을 Channel<ResultDto>를 반환하는 것으로, 결과가 수신되는 즉시 UI로 보낼 수 있습니다.
둘째는 검색 메서드에서 결과가 도착하는 대로 각 코루틴으로부터 끊김 없이 결과를 수신할 수 있도록 하는 방법입니다.
이를 위해 각 코루틴은 응답을 가져오고 처리할 때 단일 채널을 통해서 결과를 전송합니다.
이렇게 하면 호출자는 콘텐츠 인덱서로부터 얻은 결과를 즉시 수신하게 되고 UI는 그 결과를 점차적으로 표시함으로써, 사용자에게 부드러우면서 빠른 경험을 할 수 있게 도와줍니다.
채널의 유형과 역압(BackPressure)
Channel의 send()는 일시 중단 함수입니다.
그 이유는 실제로 데이터를 수신하는 누군가가 있을 떄까지 전송하는 코드를 일시 중지하고 싶을 수 있기 때문입니다.
이를 흔히 역압(backpressure)이라 하며, 리시버(reciver)가 실제로 처리할 수 있는 것보다 더 많은 요소들로 채널이 넘치지 않도록 도와줍니다.
역압을 구성하기 위해 채널에 대한 버퍼를 정의할 수 있습니다.
채널을 통해 데이터를 보내는 코루틴은 채널 안의 요소가 버퍼의 크기에 도달하면 일시 중단하는 방식입니다.
채널에서 요소가 제거되는 즉시 송신자는 다시 데이터를 보냅니다.
언버퍼드 채널(Unbuffered Channel)
버퍼가 없는 채널을 언버퍼드 채널이라 합니다.
이에 대한 구현은 현재 오직 RendezvousChannel 뿐입니다. (랑데자뷰 맞습니다 ㅋ)

채널 구현은 버퍼가 전혀 없어서 그 채널에서 send()를 호출하면 리시버가 receive()를 호출할 때까지 일시 중지됩니다.
fun main() = runBlocking {
val time = measureTimeMillis {
val channel = Channel<Int>() //0으로 자동 초기화 -> 언버퍼드 채널
val sender = GlobalScope.launch {
repeat(10) {
channel.send(it)
println("Send ${it}")
}
}
channel.receive()
channel.receive()
}
println("Took ${time}ms")
}
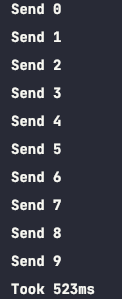
해당 예시에서 sender 코루틴은 채널을 통해 최대 10개의 숫자까지 보낼 수 있습니다.
그러나 실행이 끝나기 전까지 채널로부터 수신하는 요소가 두 개 뿐이어서 두 요소만 전송됩니다.
결과는 다음과 같습니다.

버퍼드 채널
두 번째 유형의 채널은 버퍼를 가지는 채널입니다.
앞에서 언급한 바와 같이 이 유형의 채널은 채널 내 요소의 수가 버퍼의 크기와 같을 때마다 송신자의 실행을 중지합니다.
버퍼의 크기에 따라 몇 가지 종류의 버퍼드 채널이 있습니다.
LinkedListChannel
중단 없이 무한의 요소를 전송할 수 있는 채널입니다.
이 채널 유형은 어떤 송신자도 중단하지 않습니다.
fun main() = runBlocking {
val time = measureTimeMillis {
val channel = Channel<Int>(Channel.UNLIMITED)
val sender = GlobalScope.launch {
repeat(10) {
channel.send(it)
println("Send ${it}")
}
}
delay(500)
}
println("Took ${time}ms")
}
ArrayChannel
이 채널 유형은 버퍼 크기를 0부터 최대 int.MAX_VALUE - 1 까지 가지며, 가지고 있는 요소의 양의 버퍼 크기에 이르면 송신자를 일시 중단합니다.
int.MAX_VALUE보다 적은 값을 Channel()에 전달하는 방식으로 생성할 수 있습니다.
fun main() = runBlocking {
val time = measureTimeMillis {
val channel = Channel<Int>(4)
val sender = GlobalScope.launch {
repeat(10) {
channel.send(it)
println("Send ${it}")
}
}
delay(500)
println("Taking two")
val job = GlobalScope.launch {
repeat(2) {
channel.receive()
}
}
job.join()//대기
}
println("Took ${time}ms")
}
책에서는 take(2).receive()를 사용하였는데, take 메서드가 존재하지 않아서 코드를 조금 변형하였습니다.
ConflatedChannel
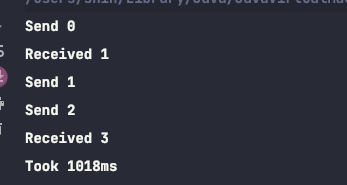
내보낸 요소가 유실되어도 괜찮다는 생각이 깔려 있는 버퍼드 채널입니다.
이 유형의 채널은 하나의 버퍼만 가지고 있으며, 새로운 요소가 보내질 때마다 이전 요소는 유실됩니다.
또한 송신자가 절대로 일시 중지되지 않는다는 것을 의미합니다.
fun main() = runBlocking {
val time = measureTimeMillis {
val channel = Channel<Int>(Channel.CONFLATED)
val sender = GlobalScope.launch {
repeat(10) {
channel.send(it)
delay(300)
println("Send ${it}")
}
}
delay(500)
val element = channel.receive()
println("Received $element")
delay(500)
val element2 = channel.receive()
println("Received $element2")
//sender.join() 10개를 다 송신할 때까지 기다림
}
println("Took ${time}ms")
}
2. 원자성 위반
원자성 위반이라는 동시성 오류 유형이 있습니다.
이 유형의 오류는 정확한 동기화 없이 객체의 상태를 동시에 수정할 때 발생합니다.
1장에서 봤던 예는 매우 간단했습니다.
서로 다른 스레드에 있는 여러 코루틴이 객체의 상태를 수정했기 때문에 일부 수정 사항이 유실됐습니다.
원자성 위반은 코틀린에서도 발생할 수 있지만, 오류를 피할 수 있도록 디자인하는 데 도움이 되는 기본형을 제공합니다.
원자성이 무엇을 의미하고 원자성 위반이 어떻게 발생하는지 제대로 이해한다면 코드를 어떻게 작성해야 원자적으로 실행될 수 있는지 알 수 있을 것입니다.
원자성
소프트웨어 실행의 관점에서 연산이 단일하고 분할할 수 없을 때 이 연산을 원자적이라 합니다.
공유 상태에 관해 언급할 때 흔히 많은 스레드에서 하나의 변수를 읽거나 쓰는 것에 대해 언급합니다.
변수의 상태를 수정하는 것은 일반적으로 변수 값을 읽고 수정하고 업데이트된 값을 저장하는 것 처럼 여러 단계로 구성되어 있습니다.
보통 이렇게 원자적이지 않아서 문제가 발생합니다.
동시성 애플리케이션을 실행하게 되면 공유 상태를 수정하는 코드 블록이 다른 스레드의 변경 시도와 겹치면서 이런 문제가 발생합니다.
예컨대 한 스레드가 현재 값을 바꾸는 중에 아직 쓰지는 않은 상태에서 다른 스레드가 현재 값을 읽을 수 있습니다.
이런 상황은 하나 또는 그 이상의 공유 상태에 대한 변경사항이 덮어 씌워져 유실될 수 있음을 의미합니다.
간단한 예를 살펴보겠습니다.
private var counter = 0
fun increment() {
counter ++
}
순차적으로 실행하면 counter값에 대하여 걱정할 필요 없이 increment()를 원하는 만큼 호출할 수 있습니다.
그러나 여기에 동시성을 추가하면 내부의 많은 것들이 바뀝니다.
private var counter = 0
fun asyncIncrement(by: Int) = GlobalScope.async {
for (i in 0 until by){
counter ++
}
}
fun main() = runBlocking {
val workerA = asyncIncrement(2000)
val workerB = asyncIncrement(100)
workerA.await()
workerB.await()
println("counter [${counter}]")
}
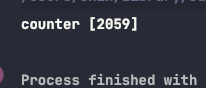
counter의 값이 종종 2100보다 낮습니다.
이는 counter++를 수행하는 코드가 원자적이지 않아서 발생합니다.
이 한 줄의 코드는 일기, 수정 및 쓰기의 세 가지 작업으로 나눌 수 있으며, 스레드가 작동하는 방식 때문에 한 스레드의 쓰기 변경사항이 다른 스레드에서 값을 읽거나 수정할 떄 보이지 않을 수 있습니다.
(233 p)
'모각코 > 2022 하계 모각코 : 꿀단지' 카테고리의 다른 글
| [모각코] 2022 하계 모각코 4회차 결과 (0) | 2022.07.24 |
|---|---|
| [모각코] 2022 하계 모각코 4회차 목표 (0) | 2022.07.24 |
| [모각코] 2022 하계 모각코 3회차 목표 (0) | 2022.07.17 |
| [모각코] 2022 하계 모각코 2회차 결과 (0) | 2022.07.10 |
| [모각코] 2022 하계 모각코 2회차 목표 (0) | 2022.07.10 |